Understanding Karpenter Consolidation and Disruption
Discover how Karpenter’s consolidation and disruption strategies optimize Kubernetes clusters for cost savings, efficiency, and seamless scaling. Learn key methods, management tools, and best practices to streamline your cloud infrastructure.
What if your Kubernetes clusters could automatically adapt to demand while minimizing costs and maintaining performance, all without manual intervention? This is the promise of Karpenter, a cutting-edge tool that transforms how Kubernetes handles scaling, consolidation, and node management.
Karpenter doesn’t just scale up or down—it optimizes your entire cluster by consolidating unnecessary nodes and minimizing disruptions during workload changes. The result? Significant cost savings, improved resource utilization, and smoother transitions for your workloads. However, to unlock its full potential, understanding the balance between consolidation and disruption is essential.
In this guide, we’ll explore how Karpenter leverages these two mechanisms to create a more efficient, responsive Kubernetes environment, and how you can harness them for optimal cost management, better performance, and seamless scaling.
Introduction to Karpenter Consolidation and Disruption
Managing Kubernetes clusters can be complex, especially when you’re handling numerous services and workloads with varying demands. Karpenter, an open-source cluster autoscaler, takes on the heavy lifting by dynamically scaling your infrastructure based on real-time demand. This means you can effortlessly add or remove nodes based on the current workload needs, which prevents resource over-provisioning and underutilization.
However, Karpenter does much more than just scale nodes. It also offers powerful tools for consolidating and disrupting resources, allowing you to optimize performance without compromising efficiency. Karpenter uses advanced algorithms to make decisions based on data from your workloads, such as CPU usage, memory consumption, and other key factors.
This flexibility is particularly important for optimizing large, dynamic environments with varying application loads.
The Importance of Consolidation and Disruption in Optimizing Cluster Efficiency
To fully optimize your Kubernetes clusters, it’s essential to understand how to manage both consolidation and disruption effectively. Consolidation refers to the process of reducing under-utilized nodes, which helps save costs and ensures that resources are allocated where they are most needed.
In contrast, disruption refers to the strategic termination or scaling of nodes to maintain cluster health and efficiency.
Both consolidation and disruption work together to ensure that your clusters are always running at peak efficiency. Consolidation prevents waste by eliminating excess resources, while disruption ensures that you are scaling in a manner that prevents bottlenecks or overloads.
The combination of these two strategies not only reduces operational costs but also allows your Kubernetes infrastructure to adapt quickly to changing workload demands.
Disruption Methods
To maintain a seamless and efficient Kubernetes environment, understanding the various disruption methods is crucial. These methods help ensure that your workloads continue to perform without interruptions while optimizing resources.
Automated Methods
Karpenter’s automation capabilities are essential for streamlining cluster management, particularly when it comes to disruptions. Automation frees you from having to manage nodes manually and allows your cluster to scale up or down based on real-time data. Here are some of the automated methods that Karpenter employs:
- Expiration: Karpenter automatically expires nodes that have surpassed their useful lifespan, meaning that once a node’s job is done, it’s removed from the cluster. This eliminates the need for manual interventions, ensuring you’re not wasting resources.
- Drift: If Karpenter detects that a node’s resource allocation is drifting from what’s required (for instance, it’s running inefficiently or using too many resources), it can take corrective actions to re-balance the workload.
- Consolidation: Nodes that are underutilized are automatically consolidated. This means Karpenter will redistribute workloads to other nodes, which optimizes your overall infrastructure and eliminates unnecessary overhead.
These methods allow you to focus on more strategic tasks while Karpenter handles the day-to-day scaling decisions, ensuring that your clusters are efficient and cost-effective.
Manual Methods for Node and NodePool Deletion Using kubectl
While automation does much of the heavy lifting, you still have control when you need it. Using kubectl, you can manually delete nodes or NodePools, which is especially useful for situations that require immediate action, such as decommissioning outdated nodes or scaling back temporarily. This will allow you to take precise, hands-on control over your cluster when needed.
Controlling Disruptions with Kubernetes Finalizers
Kubernetes finalizers are an important tool in preventing the unintended deletion of resources. When Karpenter initiates a node or Pod deletion, finalizers act as safety checks to ensure that all related tasks are properly completed before any resource is removed.
This will give you peace of mind that Karpenter won’t prematurely disrupt services or workloads, as it ensures that all dependent resources are appropriately cleaned up before deletion.
By choosing the right disruption methods, whether automated or manual, you can strike the perfect balance between efficiency and stability, ensuring your clusters remain resilient and cost-effective during scaling and consolidation processes.
Consolidation Mechanisms
When it comes to optimizing Kubernetes clusters, consolidation mechanisms play a pivotal role in reducing overhead and improving resource efficiency.
Let’s take a look at a few mechanisms.
Empty Node, Single Node, and Multi-Node Consolidation
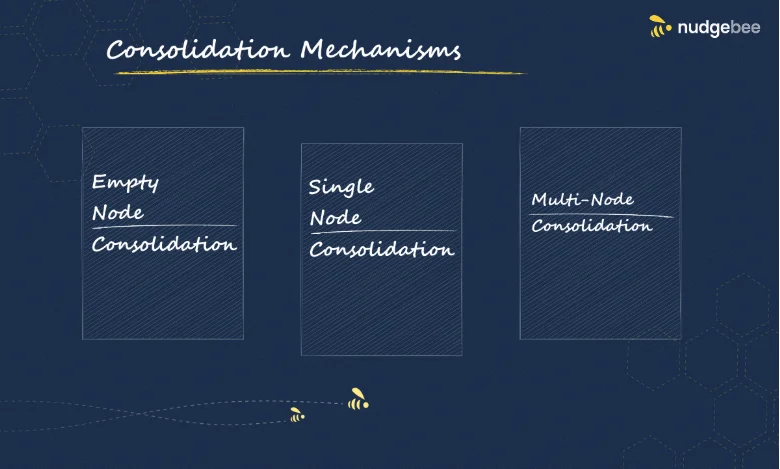
One of Karpenter’s most powerful features is its ability to intelligently consolidate nodes. This ensures that resources are only used when absolutely necessary, which can drastically reduce operational costs. Here’s how Karpenter approaches consolidation:
- Empty Node Consolidation: When a node is essentially empty, with little to no workload running, Karpenter will recognize that the node is wasting resources and will automatically remove it from the cluster. This not only reduces costs but also makes space for more critical workloads.
- Single Node Consolidation: If you have workloads that can easily be grouped onto a single node, Karpenter can consolidate them, freeing up other nodes. This reduces the overall number of nodes running in the cluster, improving both efficiency and cost-effectiveness.
- Multi-Node Consolidation: For larger workloads, Karpenter can redistribute resources across multiple nodes, ensuring that workloads are balanced while minimizing resource waste.
By using these consolidation mechanisms, Karpenter enables you to maintain a flexible, highly efficient Kubernetes environment, whether you’re running small services or resource-intensive applications.
Node Replacement Strategies for Cost Efficiency
Sometimes, a node may not be the right fit for a workload anymore. Karpenter’s node replacement strategies focus on swapping out inefficient or under-performing nodes with more appropriate alternatives.
For example, if you’re running a database on a general-purpose node, Karpenter might replace it with a more specialized instance to handle the workload more effectively. This strategy optimizes costs and ensures that your workloads always run on the best possible infrastructure.
Consolidation Preferences Based on Workload Characteristics
Not all workloads are the same, and their needs vary based on factors like CPU requirements, memory consumption, and other specific resource demands. Karpenter allows you to set consolidation preferences based on workload characteristics, ensuring that only the right nodes are chosen for each task.
For example, Karpenter can prioritize high-CPU nodes for compute-heavy applications or opt for memory-optimized nodes for database workloads. This ensures that resources are allocated in a way that minimizes waste while maximizing performance.
By understanding and implementing these consolidation strategies, you can ensure that your Kubernetes clusters operate at their full potential, with minimal waste and maximum cost-effectiveness.
Managing Node Disruption
Node disruption is an inevitable part of Kubernetes management, but how you handle it can make all the difference in maintaining the stability and performance of your clusters.
Utilizing the Disruption Controller to Manage Disruptable Nodes
In Kubernetes, some nodes can be safely terminated or scaled down, while others must remain operational to avoid disruptions. The Disruption Controller enables you to control which nodes can be disrupted based on factors such as health, workload criticality, and other operational considerations. This ensures that Karpenter only terminates nodes that won’t cause significant disruption to your services, keeping your workloads stable even during scaling events.
Node Termination Process Aligned with Kubernetes Shutdown Model
When a node is marked for termination, Karpenter adheres to Kubernetes’ graceful shutdown process. This means that before a node is decommissioned, Kubernetes will safely terminate the pods running on it, preventing any service interruptions. By following this shutdown model, Karpenter ensures that your applications stay up and running, even as nodes are being scaled down.
Handling Special Disruption Cases
In some cases, disruptions aren’t as simple as terminating a node. Drift (when nodes start to diverge from their optimal state) and interruptions (when workloads are unexpectedly disturbed due to scaling events) require special handling. Karpenter detects these disruptions early on and takes corrective actions to mitigate their impact, such as redistributing workloads to other nodes or adjusting resource allocations.
By effectively managing node disruption, you ensure that your Kubernetes clusters remain resilient, scalable, and optimized, providing a seamless experience for your applications.
Node-Level and Pod-Level Disruption Controls
To ensure that Kubernetes clusters remain resilient and workloads uninterrupted, managing disruptions at both the node and pod level is crucial. Let’s take a look.
Annotations to Prevent Voluntary Disruptions at Node and Pod Levels
To further safeguard against unnecessary disruptions, Karpenter allows you to use annotations to prevent voluntary disruptions at both the node and pod levels. This feature gives you fine-grained control, allowing you to exclude certain resources from disruption processes, which can be useful for high-priority workloads or sensitive applications that require constant uptime.
Configuring Disruption Budgets to Manage and Limit Disruptions
By setting up PodDisruptionBudgets (PDBs), you can configure how many pods can be disrupted at any given time. Karpenter respects these budgets, ensuring that disruption limits are never exceeded. This allows you to strike a balance between keeping your cluster resource-efficient while maintaining the availability and performance of your most critical applications.
Pod Disruption Budget Compliance
Karpenter fully integrates with your PodDisruptionBudgets, ensuring that any disruption event adheres to the specified limits. This compliance helps you maintain the integrity of your applications, ensuring that they are resilient even during scaling and disruption activities.
Effectively managing disruptions at both the node and pod levels helps preserve cluster stability, ensuring that your applications continue to run seamlessly, even during changes or updates.
Practical Application and Strategies
When it comes to optimizing Kubernetes clusters, the real value of Karpenter’s consolidation and disruption strategies shines through in practical application. These strategies don’t just live in theory—they directly translate into measurable improvements in cost efficiency, resource utilization, and workload management.
Examples of Demand-Driven and Cost-Based Consolidation Strategies
There are two primary approaches to consolidation: demand-driven and cost-based. In a demand-driven strategy, Karpenter adjusts resources based on real-time application requirements, scaling resources up or down as needed. In a cost-based strategy, Karpenter prioritizes reducing costs by removing unnecessary resources, even if it means scaling down resources in a way that doesn’t directly correspond to immediate workload needs. Both strategies can be used in combination, depending on the goals and constraints of your infrastructure.
AI/ML workloads are notorious for their dynamic and fluctuating resource demands. With Karpenter, you can ensure that your infrastructure is flexible enough to handle the spikes in processing power needed for these workloads, while also consolidating resources when demand decreases.
By dynamically managing resources, Karpenter enables AI/ML workloads to run more efficiently and cost-effectively.
Preferred Node Settings for Specific Application Scenarios
Karpenter allows you to define preferred node settings for different types of applications. For example, if you’re running a web service that requires low-latency connections, Karpenter can provision nodes with the appropriate networking capabilities. If you’re running a batch processing job that requires large amounts of storage, Karpenter can select nodes optimized for storage-heavy workloads.
By tailoring node settings to specific application needs, Karpenter ensures that each workload is assigned the right infrastructure.
How Nudgebee Enhances Karpenter Consolidation and Disruption

While Karpenter excels at automating node provisioning and consolidation, it lacks deep observability and real-time insights into how these changes impact overall cluster efficiency. This is where NudgeBee comes in, providing AI-driven analytics, intelligent monitoring, and actionable insights to enhance Karpenter’s capabilities.
By integrating Nudgebee with Karpenter, you gain enhanced visibility, predictive scaling, and optimized cost management, ensuring that every node decision aligns with both performance and budget goals.
1. Real-Time Node and Pod Monitoring
Nudgebee provides continuous tracking of node and pod metrics, ensuring you have complete visibility into your Kubernetes environment. With live dashboards, you can monitor real-time CPU, memory, and resource utilization, helping you make informed scaling and consolidation decisions.
Additionally, automated alerts notify you of underperforming or idle nodes, allowing for proactive consolidation before inefficiencies impact workloads. Nudgebee also offers drift detection, automatically identifying and correcting misconfigured nodes to prevent disruptions and maintain optimal cluster performance.
2. Predictive Insights for Cost-Efficient Scaling
Nudgebee’s AI-powered analytics bring intelligence to cluster management, helping you forecast demand and optimize node allocation with precision. By analyzing historical trends, it predicts traffic spikes and recommends the best scaling strategy to ensure smooth operations. It also identifies the most cost-efficient instance types based on real-world usage patterns, reducing waste and improving resource allocation.
Furthermore, by dynamically adjusting node provisioning, Nudgebee prevents over-provisioning, ensuring that your Kubernetes environment remains both cost-effective and highly performant.
3. Enhanced Disruption Management & Compliance
Managing disruptions effectively is crucial for maintaining Kubernetes stability, and Nudgebee plays a key role in minimizing their impact. By visualizing disruption patterns, it enables proactive mitigation strategies, reducing the likelihood of unexpected downtime.
Automated alerts keep you informed about potential terminations before they affect workloads, giving you time to take corrective action. Additionally, Nudgebee ensures compliance with Pod Disruption Budgets (PDBs), preventing excessive pod disruptions and keeping critical applications running smoothly.
With real-time insights, predictive scaling, and robust disruption management, Nudgebee acts as a powerful extension to Karpenter, optimizing Kubernetes clusters for peak performance and cost efficiency.
Conclusion
Managing Kubernetes clusters effectively goes beyond just provisioning resources—it’s about smart scaling, cost optimization, and minimizing disruptions. By combining Karpenter’s dynamic scaling capabilities with Nudgebee’s AI-driven insights and real-time monitoring, you can unlock a new level of efficiency in your Kubernetes environment. Together, these tools allow you to optimize workloads, reduce waste, and maintain seamless application performance, regardless of the challenges that come your way.
With Nudgebee’s predictive analytics and Karpenter’s powerful automation, you will gain the ability to make data-backed decisions that directly impact your infrastructure’s performance and bottom line.